Input Handling
Proper input handling is, in many ways, an important aspect in providing both a user friendly and secure web application today. It accomplishes this by ensuring the user understands the expected values they should be entering into fields within the application as well as protecting the system from malicious attempts to subvert the constraints put in place. It essentially boils down to making sure any user provided data has been vetted so that it will not cause any harm or unexpected behavior when used within its intended context.
Input handling encompasses a few different things, but can be confusing as to what the purpose is of each type of input handling and how they help. In fact, in some cases they can actually assist each other in their purposes. In this post we’ll talk through what each type is and what it accomplishes within our applications.
Why it Matters
Before we get too deep into what each one does and accomplishes we should first better understand why they’re important to have. To explain this further we’ll talk about two risks that we place in our web applications when we don’t implement proper input handling. Those two risks are invalid or corrupt data and code injection.
Corrupt Data
Corrupt or invalid data is about ensuring that the user provided data matches the expected type of data for which it will be used as within the system. As an example, let’s say we have a registration form that includes an input field for the user’s email. If the user enters something other than an email and we are not checking for this our system will either store it as is or throw an exception at some point in the operation. If it makes it into our data store we’re left with invalid emails that may be critical to the business of our application and result in improper behavior for other functionality (such as attempting to send offers to the user’s email address, but it’s invalid).
Code injection
Code injection is an attack that involves the potential for someone to be able to inject their own code into our system that can execute as if it were part of the expected functionality. There are two types of code injection that can be considered when building web applications: cross-site scripting and SQL injection.
Cross-site Scripting
Cross-site scripting is a type of code injection that is accomplished when someone can enter in a value like <script>alert('unsafe input was permitted!');</script> as part of their input which is then executed by the browser whenever any user visits our web application. Now this doesn’t seem that concerning with that example input, but imagine they could include more invasive code that can do something like read sensitive user information such as the identifier we’re using to indicate who the user is within our application. This is also happening for any user that’s visiting our site. We can imagine it being taken even further so that the information isn’t just shown as an alert to the user being attacked, but rather it actually sends the information behind the scenes to the attacker who injected it.
This is a very high risk that we don’t want to take as it can damage our product and reputation. More details on cross-site scripting can be found at OWASP.
SQL Injection
SQL injection is a type of code injection that is accomplished when someone can enter SQL commands and scripts as part of their input which is then executed by the database. A very well known comic summarizes the issue quite well:

The major risk here is someone being able to harm our system (such as completely deleting our database) or extract sensitive information found within it. More details on SQL injection can be found at OWASP.
Types of Input Handling
Now that we have some background as to why we should be using proper input handling let’s take a look at the different types of it. There are three main types that we’ll discuss further:
Input Sanitization
If we think about sanitization in its practical sense it’s about getting rid of something unwanted that would otherwise make things dirty or unclean. Applying this understanding to what sanitizing user input would accomplish we can expect that it will get rid of unwanted data that was inserted as part of the user data. We know from earlier that there’s a risk of someone injecting code as part of their input and this is exactly what input sanitization can address. We can use sanitization to identify targeted keys within the user provided data and remove them completely so that they cannot cause any harm or do anything malicious.
Sanitization Example:
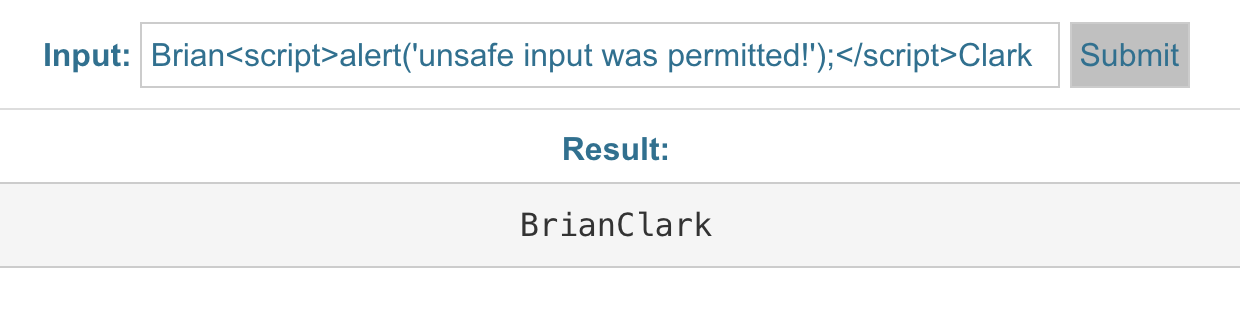
Input Escaping
We all understand what escaping means in a practical sense, but how does this apply to user input? Well it handles things in a similar sense to that of sanitization in that it identifies targeted keys within the user provided data, but what it does once a key is identified is different. Instead of cleaning out the identified keys, escaping converts the characters of those keys to their encoded values for the context they will be used in. As an example let’s say we have input that will be used in HTML and contains the following data: <script>alert('unsafe input was permitted!');</script>. Input escaping, in this example, will convert the more dangerous characters (<, >, etc.) to their HTML encoded equivalent. This makes the input safe to be used within HTML and renders the complete value provided by the user.
Escaping Example:
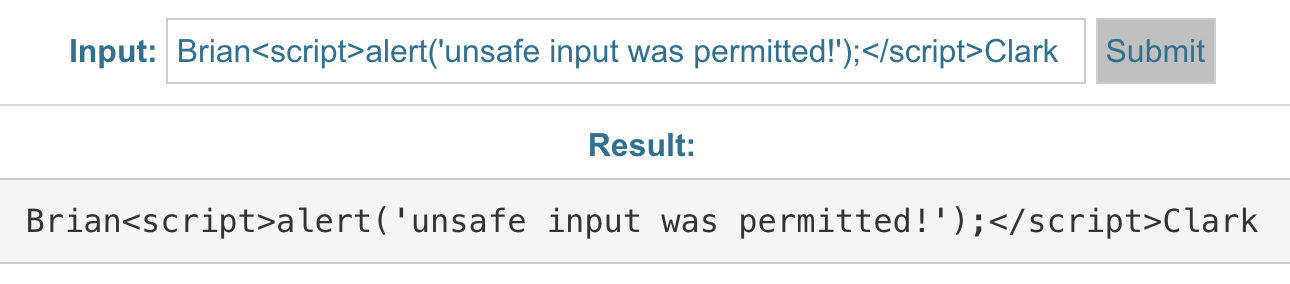
Input Validation
Input validation is the process of confirming something is true to its expected type. This makes sure the data provided is up to par with the various constraints that are used to enforce a value is of a certain type. We can think of this as making sure an email entered by a user is indeed an email up to the standards we expect of an email value. These constraints can be that the email must contain only one ampersand (@), it must have a proper top level domain (.com, .net, etc.) and many more bounds to determine the legitimacy of a value as an email.
Validation Example:
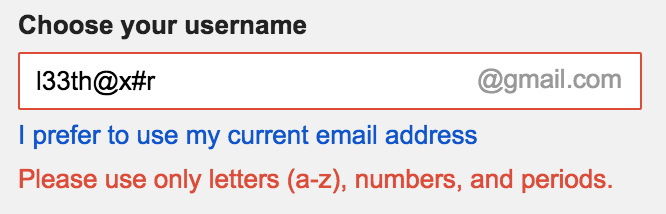
Conclusion
With this understanding of input handling now we can go forth in implementing these techniques to provide a better experience and more secure web application for our users. Feel free to comment with any questions below.